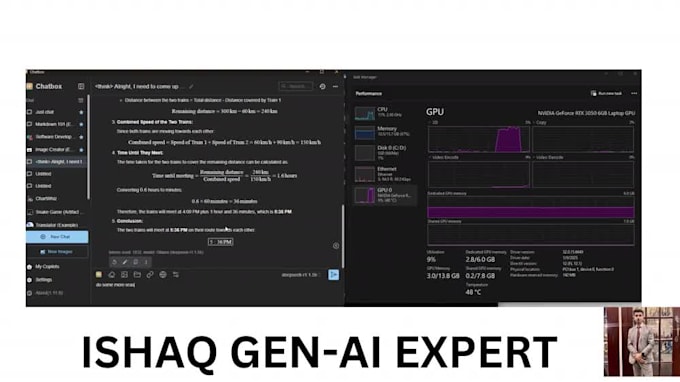
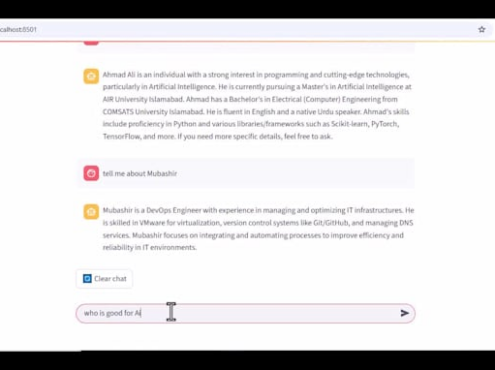
I offer assistance in setting up and deploying Large Language Models (LLMs) locally on your GPU using Ollama, covering installation, environment configuration, and building a FastAPI backend for easy interaction via REST APIs or a custom application.
This service provides a complete local AI environment enabling you to:
Install and configure Ollama for seamless model deployment.
Execute cutting-edge LLMs locally without dependence on external cloud services.
Develop a FastAPI service for sending queries and receiving immediate responses.
Establish a chat interface for direct communication with the model.
Incorporate the LLM into existing applications or processes.
Optionally fine-tune and optimize the model for specific needs.
This solution is ideal for those who wish to:
Maintain data ownership and ensure local/private operations.
Develop AI-driven applications, chatbots, or assistants utilizing Ollama.
Test rapid, GPU-accelerated AI workflows.
Deploy a production-ready LLM with API access and documentation.
For developers, researchers, or businesses aiming to leverage AI locally, I will deliver a fully operational and documented solution customized to your requirements.